
Descobre a nova e brutal capacidade de criação de imagens da OpenAI, agora grátis no ChatGPT! Cria, edita e até adiciona texto às tuas imagens com a IA. Lê já!
Índice
Introdução ao 4o Image Generation
A OpenAI acaba de lançar uma enorme atualização nas suas capacidades de criação e edição de imagens, integrada diretamente no ChatGPT e o melhor de tudo é que está disponível até nas contas gratuitas. Se achavas que a IA Generativa já era impressionante, espera até veres o que podes fazer agora.
Vamos mergulhar a fundo nesta novidade brutal e descobrir tudo o que podes fazer com esta nova capacidade.
O Que Fez a OpenAI?
A sério, a nova Geração de Imagens da OpenAI é absolutamente incrível. Já não se trata apenas de criar imagens como queres, superrealistas, de homens, de mulheres, ou o que a tua imaginação ditar. Agora, podemos fazer coisas absolutamente impressionantes com um controlo sem precedentes.
Podes pedir uma infografia detalhada sobre um processo complexo, como a integração da IA em empresas, que foi o que eu fiz e repara abaixo no que o ChatGPT com a nova capacidade de imagem criou e vê como o texto está correto, com as diferentes partes bem definidas e o mais espantoso é que podemos editar o que quisermos depois. Esta nova capacidade é absolutamente brutal.
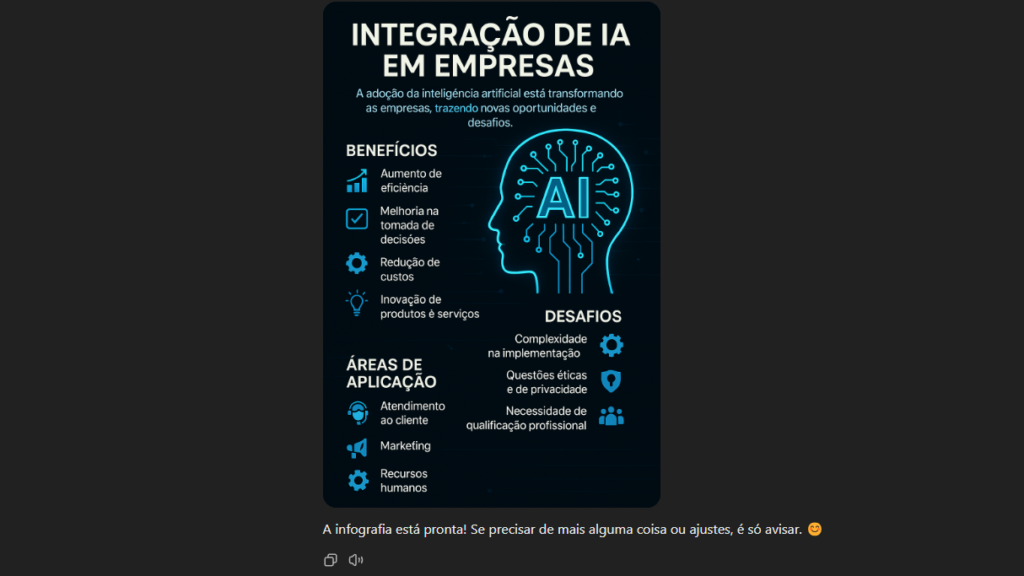
Esta capacidade de criar imagens diretamente no ChatGPT não é um novo conceito, pois já se tinha anunciado há bastante tempo, quando foi o lançamento do GPT-4o, que era multimodal (capaz de processar diferentes tipos de informação, como texto e imagem).
Naquela altura (no ano passado, 2024), o Greg Brockman (Presidente e Co-Fundador da OpenAI) partilhou uma imagem com texto integrado, que fez com que toda a gente ficasse de boca aberta, porque à data a IA mal conseguia fazer texto corretamente nas imagens. Além disso, o realismo da imagem era incrível, muito superior ao que o DALL·E (o modelo anterior da OpenAI para imagens) conseguia fazer na altura.
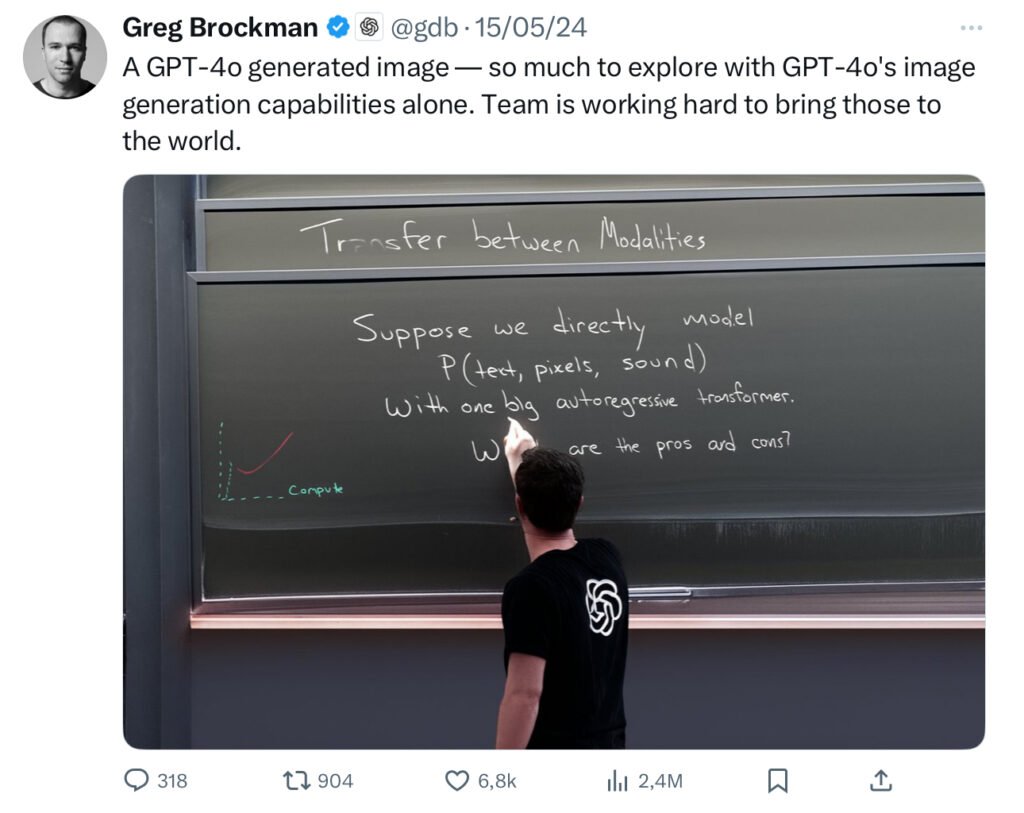
Desde então, o ChatGPT manteve esta Geração de Imagem Nativa, baseada no modelo GPT-4o, mais resguardada e que é um conceito semelhante ao que o Google apresentou com o Gemini, a mesma rede neural que cria o texto também cria as imagens.
E Porque é Que Isto é Tão Importante?
Porque é um processo completamente distinto do que utilizam as IAs de criação de imagens mais tradicionais, como o Midjourney. Agora, o que acontece é que o processo permite um controlo muito maior, já que a rede neuronal está a processar toda a informação, nomeadamente, o teu pedido em texto, o contexto da conversa e a própria imagem que está a criar ou a editar, pelo que não está apenas a focar-se em fazer a imagem e isto dá-lhe a capacidade de fazer coisas que um modelo com foco exclusivamente em imagem não consegue.
Esta capacidade foi lançada “assim, de repente“, mas a realidade é que o anúncio parece ter sido uma resposta estratégica ao anúncio do Gemini 2.5 Pro pelo Google (que, diga-se de passagem, é atualmente um dos modelos de IA mais inteligentes do mundo).
Esta capacidade de imagem é algo que toda a gente vai poder utilizar, pois tendo em conta que o Google oferece funções semelhantes gratuitamente dentro do AI Studio, a OpenAI não teve outra opção senão disponibilizá-la para todas as contas. Sim, estás a ler bem, até as contas gratuitas podem utilizar o modelo de imagem do GPT-4o!
O Que Torna Esta IA de Imagem Tão Revolucionária?
A palavra brutal não é um exagero. Esta atualização representa um marco significativo na criação de imagens com IA. Vamos detalhar os pontos que a tornam tão especial:
- Qualidade e Realismo Impressionantes: As imagens criadas atingem um nível de detalhe, coerência e fotorrealismo que rivaliza, e em muitos casos supera, os melhores modelos do mercado. Tanto se lhe pedires uma cena fantástica ou um retrato hiperrealista, a IA da OpenAI entrega-te resultados espantosos.
- Compreensão Profunda do Texto (Prompting): Devido à inteligência subjacente do GPT-4o, o modelo tem uma capacidade notável de compreender nuances, detalhes complexos e até mesmo o “sentimento” do teu pedido. Podes ser incrivelmente específico sobre iluminação, ângulo da câmara, estilo artístico, emoções das personagens e a IA esforçar-se-á por capturar essa intenção.
- Criação de Texto Coerente Dentro das Imagens: Este é um dos maiores avanços. Ser capaz de criar texto legível e contextualmente correto dentro de imagens era um desafio enorme para a maioria das IAs, agora, podes pedir cartazes, capas de livros, memes, T-shirts com slogans ou até vinhetas de banda desenhada e o texto aparecerá de forma surpreendentemente precisa.
- Edição Intuitiva e Contextual: Esquece as ferramentas complexas de edição de imagem, agora podes pedir diretamente ao ChatGPT para modificar partes da imagem criada, por exemplo, podes pedir-lhe “Torna o cão mais novo“, “Muda a cor da camisola para azul“, “Adiciona óculos de sol à pessoa“. A IA não se limita a “colar” elementos, ela recria a imagem e mantém a coerência geral, ou seja, ela compreende o contexto da alteração.
- Capacidade Multimodal Real: Podes fazer upload de uma imagem e pedir à IA para a utilizar como referência, combiná-la com outra ideia ou modificá-la. Também podes pedir para criar um anúncio com base numa imagem de um produto que lhe enviaste ou com base em informação retirada de um link. Esta capacidade de receber imagens como input e criar imagens como output, tudo dentro da mesma conversa e sempre a compreender o texto é o que define um verdadeiro modelo multimodal.
- Criação de Estruturas Complexas (Infografias, BDs): A IA pode agora estruturar informação visualmente complexa, como infografias ou páginas de banda desenhada com múltiplas vinhetas e diálogos e para tal pode seguir um tema que lhe forneças ou inventar um guião.
- Acessibilidade: O facto de estar disponível gratuitamente (com limites, claro) para milhões de utilizadores do ChatGPT, torna-a uma ferramenta criativa extremamente poderosa.
Como Funciona a Magia Multimodal
A diferença fundamental reside na arquitetura. Os modelos como o Midjourney ou o Stable Diffusion são primariamente “diffusion models” treinados especificamente para traduzir texto em imagens. Eles são excelentes nisso, mas operam de forma um pouco isolada do entendimento linguístico profundo.
O GPT-4o, por outro lado, é um modelo inerentemente multimodal, que foi treinado desde o início para processar e criar informação em diferentes formatos (texto, áudio, imagem).
Quando lhe pedes para criar uma imagem, não é um módulo separado que entra em ação de forma isolada, é a própria rede neural central do GPT-4o que interpreta o teu pedido, acede ao seu vasto conhecimento, compreende o contexto da conversa e, em seguida, cria a representação visual correspondente.
Vantagens do Image Generation
- Melhor Compreensão do Prompt: O modelo entende o significado por detrás das palavras de forma mais profunda.
- Coerência Contextual: O GPT-4o mantém o fio condutor da conversa, o que permite edições e pedidos subsequentes que fazem sentido no contexto da imagem original.
- Integração Nativa: A criação de texto ou a combinação de imagens são processos mais naturais porque o modelo “pensa” sobre todos os elementos.
- Flexibilidade: O 4o permite casos de uso híbridos, como criar texto explicativo e depois ilustrá-lo com uma imagem criada no momento ou analisar uma imagem e descrevê-la em texto.
É esta integração profunda que permite o nível de controlo e sofisticação que estamos a testemunhar.
O Que Podes Fazer Agora?
Com este modelo podemos fazer autênticas obras de arte, ele é uma revolução para a criação de imagens com IA, que vai literalmente mudar os processos de trabalho, as formas de fazer as coisas e vai pôr muito contra a parede aquelas aplicações que viviam de vender serviços para criar imagens com IA. Eu nem quero imaginar no que vai acontecer quando revelarem modelos multimodais que também podem fazer áudio ou vídeo, pois ao ver como isto funciona com imagem, vai ser absolutamente incrível.
Vamos experimentá-lo!
Simplesmente, vais à interface do ChatGPT. Aí, podes dizer-lhe para te criar uma imagem.
- Exemplo 1: Criação Básica e Realismo
Prompt: “Cria-me uma imagem de um cão na praia, muito feliz. Quero uma imagem muito realista, como se fosse tirada com uma câmara profissional num amanhecer.“
A partir daqui, vamos ver como começa a trabalhar.
O importante é que deves ver um tipo de interface específico onde a imagem é criada de cima para baixo.


Se não tens esta interface (acima) é porque ainda não tens o modelo mais recente ativo ou estás a utilizar o DALL·E (integrado). Em princípio, já deve estar disponível para todas as pessoas, mas certifica-te que vês esta interface (acima) de criação progressiva.
Eu tenho de dizer que, nos primeiros dias após o lançamento, funcionou um pouco mal, um pouco lento, mas é compreensível devido a estar totalmente saturada por ser uma autêntica loucura!

Podes ver na imagem como aparece o nosso cãozinho, que ficou muito bonito e muito bem feito, num fundo realista, muito atrativo.
- Exemplo 2: Edição Contextual
Uma vez que é uma rede neural que pode interpretar para além da imagem, vamos dizer-lhe:
Prompt Seguinte: “Faz com que o cão seja muito mais jovem.”
E a partir daqui, o que ele pode fazer é mudar a minha imagem, pois o facto de ter uma imagem nativa permite a edição da imagem, permite mudar partes da imagem sem mudar o resto e não através de um processo de inpainting básico (como faz o Midjourney, que “pinta por cima” de uma área e depois tenta disfarçar a junção), mas ao compreender que quero a mesma imagem, apenas de outra maneira.
E, assim, o que nos vai mostrar é uma imagem praticamente igual, mas com as mudanças que foram pedidas.

Como podes ver, o resultado do nosso cão é perfeito, repara nos detalhes, porque é espetacular, repara como uma pata estava levantada na imagem original e como na nova imagem está levantada exatamente (ou praticamente) da mesma forma. A imagem é praticamente a mesma, porque no final o que temos é a mesma imagem manipulada pela rede neuronal.
- Exemplo 3: Combinação de Imagens (Multimodalidade)
O ChatGPT pode combinar imagens.
Prompt: “Cria-me um homem sentado num balcão de um restaurante a olhar para a câmara.“
Vamos começar por criar uma imagem, como a que fizemos com o cão, mas desta vez de uma pessoa.

Como podes ver, o modelo fez-nos uma imagem de um homem totalmente correta e o que vamos fazer agora é pedir-lhe para inserir outra imagem e tentar que as unifique. Vou fazer upload de uma imagem de uma chávena (por exemplo, uma com o logo do ChatGPT).
Prompt Seguinte (com o upload da seguinte imagem): “Faz com que o homem segure esta chávena.“

Enviamos e vamos ver do que o ChatGPT é capaz.

O resultado é absolutamente incrível e tem a chávena inserida e integrada, o que demonstra que não é um simples “copiar e colar“, ele recriou a imagem tendo em conta que queríamos aquela imagem que lhe demos e como o modelo é multimodal, combina a imagem que criou com a imagem do upload sem qualquer problema.
- Exemplo 4: Criação de Texto Avançada (Banda Desenhada)
Mas vamos levar isto para o próximo nível, porque uma das coisas mais difíceis que sempre existiu nos criadores de imagem foi a criação de texto. Vamos ver como o ChatGPT se sai com esta nova capacidade.
Prompt: “Cria-me uma página inteira de uma banda desenhada (comic) com várias vinhetas e múltiplos textos dentro de cada vinheta. Além disso, inventa tu mesmo o guião, que seja divertido, sobre o tema da Inteligência Artificial e com um estilo de cartoon moderno específico.“
Mais difícil não lhe posso pôr! Vamos ver o que ele é capaz de fazer porque, a sério, isto vai fazer a tua cabeça explodir.

E repara no resultado! Criou uma página com várias vinhetas, manteve os estilos, a personagem e colocou o texto dentro das vinhetas. Há erros no texto, mas na realidade é absolutamente incrível que consiga fazer isto.
(Nota: A IA pode cometer pequenos erros, mas a estrutura e a informação principal costumam estar corretas. Depois o que podemos fazer é pedir que altere o que não esta tão bem.)
- Exemplo 5: Design Gráfico e Integração Web (Anúncio)
Se temos a capacidade de combinar imagens e introduzir textos, temos um designer gráfico à medida.
Vou fazer o upload de uma imagem de uma câmara fotográfica compacta.
Prompt (com o upload de uma imagem e link): “Cria uma imagem para um anúncio em formato vertical (poster) que promova esta câmara [imagem anexada]. A ideia é atrair clientes para a minha loja. Utiliza a informação sobre as características da câmara que encontras neste link do produto. Tenta criar um anúncio atrativo, simples e com letras grandes.“
Vamos dar-lhe o pedido e ver o que o ChatGPT faz, o engraçado é que estou a combinar a capacidade do ChatGPT de procurar informação na internet, compilá-la, processá-la, extrair o que precisa como um LLM e depois criar a imagem com base nisso, esta é a beleza de ter um modelo que nos permite fazer o que quisermos, da forma que quisermos e combinar como melhor nos apetecer.


Não sei quanto a ti, mas a mim parece-me incrível.
- Exemplo 6: Criação de Infografias Complexas
Para além de fazer textos, BDs, imagens realistas, manipulá-las e mudá-las, também pode fazer infografias.
Volto ao ChatGPT e digo:
Prompt (com link): “Faz-me uma infografia sobre o conteúdo deste link da biografia de Andrej Karpathy, ex-Tesla/OpenAI. Foca-te na experiência profissional desta pessoa. Dá-lhe um look atrativo, muito moderno e simplista. Pouco texto, mas sobretudo que seja uma infografia que ajude a entender a sua carreira num piscar de olhos.“
Para começar, ele entendeu o que tem de fazer e procurou informação sobre o Andrej Karpathy no link que lhe dei, analisou o conteúdo do link e sugeriu a seguinte estrutura.
Como temos uma rede neuronal que pode fazer várias coisas, ele mesmo decide quando acredita que estamos a pedir uma imagem e quando não. Podemos forçá-lo, claro, mas para processos como este, ele pode primeiro utilizar o LLM para estruturar e depois criar a imagem. O que vai dar lugar a coisas como as que já podemos fazer com o Gemini no AI Studio, que permite criar uma receita de cozinha com imagens intercaladas. Ou seja, o modelo decidirá em que momento da sua resposta deve fazer uma imagem ou texto, porque é multimodal e isso vai mudar completamente o conteúdo que criamos com IA.
Prompt Seguinte: “Agora cria a infografia numa imagem.“
(Pode dar um erro ocasional, especialmente com pedidos complexos ou quando os servidores estão sobrecarregados. Se der, é tentar novamente.)

Pois aí está! Fez uma infografia e, caso não gostes de alguma coisa, podes pedir-lhe para fazer uma alteração.
Como Começar a Utilizar
A grande notícia é a acessibilidade. A OpenAI disponibilizou esta capacidade avançada de imagem através do GPT-4o, que está disponível para todos os utilizadores do ChatGPT.
- Passos para começar:
- Acede ao ChatGPT: Vai a chat.openai.com ou abre a aplicação no telemóvel.
- Verifica o Modelo: Certifica-te que tens acesso ao GPT-4o (normalmente indicado no topo da interface ou num menu de seleção de modelo). A OpenAI está a fazer o rollout, por isso, se ainda não o tens, deverás recebê-lo em breve.
- Faz o Teu Pedido: Simplesmente escreve o que queres criar, podes começar o prompt com “Cria uma imagem de…” ou descrever a imagem diretamente.
- Observa a Criação: Se estiveres a utilizar a nova capacidade, deverás ver a imagem a ser criada progressivamente, muitas vezes de cima para baixo. Se aparecer instantaneamente ou com uma interface diferente, podes estar a utilizar o DALL·E.
- Acrescenta ao Teu Pedido e Edita: Após a imagem ser criada, podes continuar a conversa para pedir modificações, variações ou utilizar a imagem como base para novos pedidos. Podes também clicar na imagem para opções adicionais, como fazer download ou editar ao utilizar uma nova interface de edição que permite selecionar áreas e dar instruções específicas para essas áreas.
- Upload de Imagens: Procura o ícone do “+” na caixa de texto para fazeres upload das tuas próprias imagens e usá-las nos teus prompts.
Limitações a Ter em Conta
- Utilizadores Gratuitos: Terão limites no número de mensagens e imagens que podem criar com o GPT-4o. Após atingir o limite, voltarão a usar o modelo que não tem a capacidade de imagem avançada ou terão de esperar que o limite seja reposto.
- Utilizadores com Subscrição Paga: Têm limites significativamente mais altos.
- Velocidade: Devido à enorme procura, a criação de imagens pode ser mais lenta do que o ideal, especialmente nos horários de pico. A OpenAI está certamente a trabalhar na otimização e escalabilidade.
- Disponibilidade: O rollout é faseado, por isso pode levar algum tempo até que todos os utilizadores tenham acesso a todas as funções e à interface de edição mais recente.
O Impacto no Mundo Real
Isto vai mudar o mundo como o conhecemos, a nível do design gráfico, da produção audiovisual, da criação de mockups e de tudo o que possas imaginar que podemos fazer no marketing digital, é absolutamente incrível.
E está a acontecer com os designers gráficos o que aconteceu com os fotógrafos, o que aconteceu com os tradutores, o que aconteceu com todo o tipo de diferentes profissões de atendimento ao cliente.
Para além de ser divertido fazer imagens do que quiseres, podes inserir o produto que quiseres, onde quiseres, podes fazer o texto que bem entenderes e tudo isto em 30 segundos e totalmente gratuito (ou de baixo custo em comparação), é um game changer absoluto para o mundo como o conhecemos a nível da produção audiovisual e de marketing.
Assim sendo, podemos dizer que, por um lado, torna acessível a todos a criação visual, pois permite que pequenas empresas, freelancers e utilizadores criem materiais de alta qualidade sem grandes orçamentos ou conhecimentos técnicos. Por outro lado, pode levar à desvalorização do trabalho dos designers, ilustradores e fotógrafos, cujas competências podem parecer substituíveis por uma IA.
No entanto, também abre novas oportunidades, pois os profissionais criativos podem usar esta nova capacidade para acelerar o seu fluxo de trabalho, criar ideias rapidamente, criar protótipos ou focar-se em aspetos mais estratégicos e conceptuais do design que a IA ainda não domina. O domínio da prompt engineering e da edição de resultados de IA torna-se uma nova competência valiosa.
A capacidade de criar infografias, diagramas e ilustrações personalizadas pode transformar a forma como ensinamos e comunicamos ideias complexas.
A capacidade de criar imagens realistas, onde se inclui as deepfakes ou as imagens manipuladas, aumenta as preocupações sobre a desinformação.
O Dilema da OpenAI
O problema disto é que também pode ser utilizada para fins mais complexos ou controversos. O Sam Altman (CEO da OpenAI) declarou que querem diminuir muito a censura e que, quando um conteúdo poder ser ofensivo, seja o utilizador a decidir se quer criá-lo ou não, em vez da ferramenta não permitir à partida. É óbvio que isto abre a porta a uma liberdade de expressão que tem certos limites e que tínhamos visto principalmente no Grok (a IA da xAI de Elon Musk).
E os limites do ChatGPT estão um pouco difusos por agora, pois o modelo consegue já fazer certas coisas, mas continua a ter algumas barreiras.
O Sam Altman disse no X que não ser possível ainda fazer certas coisa pode ser um bug e que irá ser corrigido, por exemplo, o modelo fazer uma imagem de um “homem sexy” e não fazer de uma “mulher sexy”.
Ou seja, a OpenAI quer que o GPT-4o Image Generation tenha muito menos filtros e com isto podemos esperar que se possa fazer muito mais coisas no futuro, pelo que encontrar o equilíbrio certo entre liberdade, segurança e ética continua a ser um dos maiores desafios para empresas como a OpenAI.
Comparação com Concorrentes
Em definitivo, o que tens com esta capacidade de imagem da OpenAI é um dos modelos mais potentes do mercado. Apesar de ser um pouco lento, o que também entendo por estar a haver uma enorme quantidade de utilização agora mesmo por estar disponível há muito pouco tempo e até nas contas gratuitas, com o qual há potencialmente 100 milhões de pessoas a tentar fazer imagens com o ChatGPT, mas a realidade é que se isto acelerar um pouco mais, se se tornar mais rápido, a capacidade que teremos para criar imagens, manipulá-las, colocar textos e fazer o que quisermos pode levar-nos a limites inimagináveis.
Se compararmos o ChatGPT com a criação de imagens do Google, vemos que a diferença (em qualidade e controlo, especialmente com texto e edição) é muito grande e o ChatGPT é muito superior, apesar de mais lento, mas também temos de ter em conta que o modelo do Google, utiliza o Gemini Flash, o que explica que a qualidade seja inferior.
Vamos ver quando o Google revelar, dentro do seu novo modelo Gemini 2.5 Pro, uma capacidade de criar imagens multimodais com esse modelo tão potente, aí a competição ficará ainda mais interessante.
De seguida podes ver uma comparação rápida:
Comparação de Plataformas de IA Generativa
Desliza horizontalmente para ver toda a tabela em dispositivos móveis
| Plataformas | Pontos Fortes | Pontos Fracos |
|---|---|---|
| OpenAI (GPT-4o) |
|
|
| Midjourney |
|
|
| Google (Gemini) |
|
|
| Stable Diffusion |
|
|
A escolha depende muito das tuas necessidades específicas, se for qualidade artística pura (Midjourney), flexibilidade e controlo local (Stable Diffusion), integração e compreensão multimodal (OpenAI) e velocidade e ecossistema do Google (Gemini).
O Futuro é Multimodal e Integrado
Para mim, este é um exemplo claríssimo de como a IA está a avançar, não só em níveis de “inteligência” (sempre a subir), mas também na usabilidade e digo-te que o ChatGPT vai passar à frente de muitas das aplicações que utilizamos hoje em dia de IA, porque vai unificá-las a todas dentro de si mesmo.
Ao fim de contas, o ChatGPT fez um avanço incrível e o objetivo da OpenAI é torná-lo um assistente universal capaz de lidar com qualquer tipo de informação e tarefa.
A integração nativa e poderosa da criação e edição de imagens é um passo gigante nessa direção. O próximo passo lógico, como dito no artigo, é a integração igualmente sofisticada de áudio e vídeo.
Podes imaginar descrever uma cena e obter um pequeno clip de vídeo, ou narrar um texto e ter a IA a criar uma banda sonora apropriada ou ainda analisar um vídeo e criar legendas, transcrições ou até mesmo edições básicas. O futuro da IA é multimodal e o ChatGPT está a liderar o caminho para tornar essa visão uma realidade acessível.
Um Novo Paradigma na Criação Visual ao Teu Alcance
A nova capacidade de criação de imagens da OpenAI, integrada no ChatGPT e acessível a todos, é verdadeiramente brutal.
O 4o Image Generation representa um salto significativo na qualidade, controlo e versatilidade da IA Generativa visual, pois desde a criação de imagens hiperrealistas e a manipulação contextual até à criação de texto coerente e estruturas complexas como infografias e bandas desenhadas, as possibilidades são infinitas.
E, embora existam desafios como a velocidade atual, os limites para os utilizadores gratuitos e as contínuas questões éticas sobre filtros, o impacto desta tecnologia é inegável.
Esta nova capacidade é apenas o início da era multimodal integrada. O potencial para combinar texto, imagem, áudio e vídeo de forma fluida numa única interface promete revolucionar ainda mais a forma como trabalhamos, aprendemos e criamos.
E tu já experimentaste a nova Geração de Imagens do ChatGPT? O que achaste?
Partilha as tuas experiências nos comentários abaixo! O futuro da criação visual está a acontecer agora e tu podes fazer parte dele!

